YJIT: Building a New JIT Compiler Inside CRuby
The 1980s and 1990s saw the genesis of Perl, Ruby, Python, PHP and JavaScript: interpreted, dynamically-typed programming languages which favored ease of use and flexibility over performance. In many ways, these programming languages are a product of the surrounding context. The 90s were the peak of the dot-com hype, and CPU clock speeds were still doubling roughly every 18 months. It looked like the growth was never going to end. You didn’t really have to try to make your software run fast, because computers were just going to get faster, and the problem would take care of itself. Today, things are a little different. We’re reaching the limit of current fabrication technologies, we can’t rely on single-core performance increases to solve our performance problems, and because of mobile devices and environmental concerns, we’re starting to realize that energy efficiency matters.
Last year, during the pandemic, I took a job at Shopify, a company that has a massive server infrastructure powered by Ruby on Rails. I joined a team with multiple software engineers working on improving the performance of Ruby code in a variety of ways, ranging from optimizing the CRuby interpreter and its garbage collector, to the implementation of TruffleRuby, an alternative Ruby implementation. Since then, I’ve been working with a small team of skilled engineers on YJIT, a new JIT compiler inside CRuby.
This project is important to Shopify and Ruby developers worldwide because speed is an underrated feature. There is already a JIT compiler inside CRuby, known as MJIT, which has been in the works for 3 years, and while it has delivered speedups on smaller benchmarks, it has, so far, been less successful at delivering real-world speedups on widely used Ruby applications including Rails. With YJIT, we take a data-driven approach, and focus specifically on performance hotspots of larger applications such as Rails and Shopify Core (Shopify’s main Rails monolith).
YJIT is an attempt to gradually build a JIT compiler inside CRuby such that more and more of the code is executed by the JIT, which will eventually replace the interpreter for most of the execution. Our compiler is based on Basic Block Versioning (BBV), a JIT compiler architecture I started developing during my PhD. I’ve given a talk about YJIT in March of this year at MoreVMs 2021 workshop if you’re curious to hear more about the approach we’re taking.
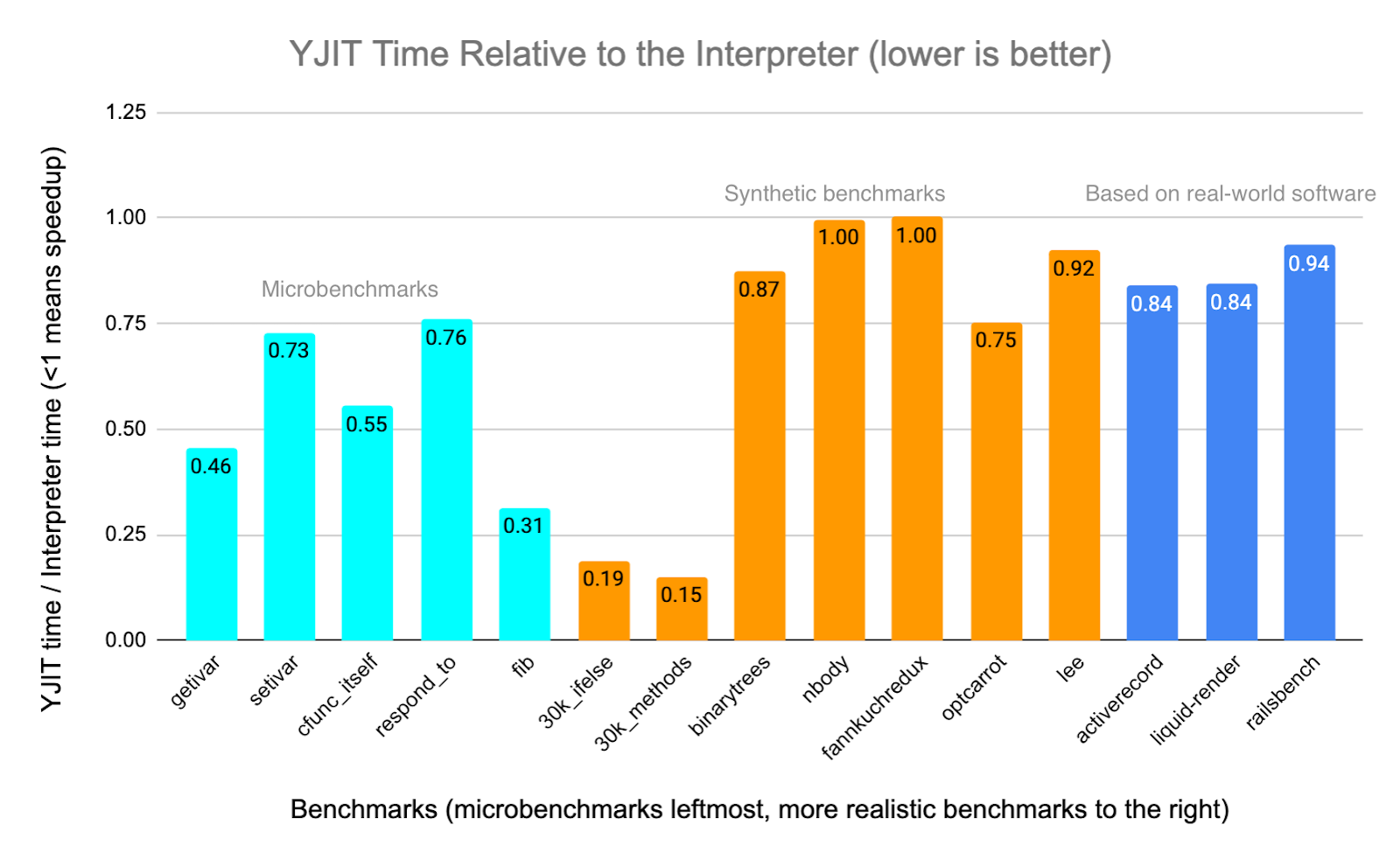
I don’t want to oversell YJIT. Our results have significantly improved since the MoreVMs talk, but are still modest. We’re very much at the early stages of this project and there are known bugs in our implementation. That being said, according to our benchmarks, we’ve been able to achieve speedups over the CRuby interpreter of 7% on railsbench, 19% on liquid template rendering, and 19% on activerecord. YJIT also delivers very fast warm up. It reaches near-peak performance after a single iteration of any benchmark, and performs at least as well as the interpreter on every benchmark, even on the first iteration.
Building YJIT inside CRuby comes with a number of limitations. It means that our JIT compiler has to be written in C, and that we have to live with design decisions in the CRuby codebase that were not made with a high performance JIT compiler in mind. However, it has the key advantage that YJIT is able to maintain almost 100% compatibility. We are able to pass the CRuby test suite, comprising about 30,000 tests, and we have also been able to pass all of the tests of the Shopify Core CI, a codebase that comprises over 3 million lines of code and depends (directly and indirectly) on over 500 Ruby gems, as well as all the tests in the CI for GitHub’s backend.
We believe that the BBV architecture that powers YJIT offers some key advantages when it comes to compiling dynamically-typed code, and that having end-to-end control over the full code generation pipeline will allow us to go farther than what is possible with the current architecture of MJIT, which is based on GCC. Notably, YJIT can quickly specialize code based on type information and patch code at run time based on the run-time behavior of programs.
Currently, only about 50% of instructions in railsbench are executed by YJIT, and the rest run in the interpreter, meaning that there is still a lot we can do to improve upon our current results. There is a clear path forward and we believe YJIT can deliver much better performance than it does now. However, as part of building YJIT, we’ve had to dig through the implementation of CRuby so we could understand it in detail. In doing so, it’s become obvious that one of the main performance challenges in implementing a fast JIT compiler in CRuby, is that key elements of the architecture are optimized with an interpreter in mind, and not a JIT compiler.
For instance, in CRuby every object instance variable read or write requires multiple pointer indirections and dynamic checks. In order to read an instance variable (ivar) from a Ruby object, one has to:
-
Check that the receiver is not an immediate value
-
Check that the receiver is not
Qnil -
Check that the receiver is a
T_OBJECT -
Check that the object class matches our inline cache
-
Read the serial number from the class (extra pointer indirection, memory access)
-
Check whether the object stores its ivars internally or on an external table
-
Potentially: read the pointer to the external table (extra memory access)
-
Potentially: check if the ivar index is within the bounds of the external table
-
Read the ivar from the object or external table
Note that at the moment, only 3 instance variable slots can be stored directly on the object itself, so instance variables are almost always on an external table in the vast majority of accesses.
As you can imagine, even though some of these checks can sometimes be optimized away, generating efficient machine code for instance variable accesses in CRuby is very difficult. It doesn’t have to be this way. This problem was solved by Self, the successor of Smalltalk, in the early 1990s. Self used what they call “maps”, but nowadays are typically referred to as object shapes (see Section 3 of An Efficient Implementation of SELF). This is tested and proven technology, used by Chrome’s V8 , Firefox’s SpiderMonkey, and TruffleRuby. If you are curious, this excellent blog post by Mathias Bynens and this great talk by Benedikt Meurer explain the concept of object shapes and shape trees in more details.
# Optimized ivar reads can be as short as three x86 instructions
# ebx = pointer to the object
cmp [ebx + <object shape offset>], <cached object shape>
jne <inline cache miss>
mov eax,[ebx, <cached ivar offset>] # load the ivar value
Thanks to object shapes, V8, SpiderMonkey and TruffleRuby are able to implement instance variable reads in as little as one single dynamic check, giving them an enormous performance advantage. We believe that with a coordinated effort that involves the Ruby Core developers, key technologies such as this could be implemented inside CRuby, and would benefit MJIT, YJIT, and any other future attempts to implement a JIT inside CRuby, and this without significantly impacting the performance of the interpreter.
Matz has stated in his recent talk at Euruko 2021 that Ruby would remain conservative with language additions in the near future. We believe that this is a wise decision as rapid language changes can make it difficult for JIT implementations to get off the ground and stay up to date. It makes some sense, in our opinion, for Ruby to focus on internal changes that will make the language more robust and deliver competitive performance in the future.
I believe that, through incremental, targeted changes, CRuby can be gradually re-engineered so that it can eventually have a true high-performance JIT compiler. Doing so must necessarily involve both JIT compiler experts and the Ruby Core developers. One key area of potential improvement would be the inclusion of object shapes. There are other things that could help us, such as rewriting some C methods in pure Ruby, such as Array#each and Fixnum#times, so that JIT compilers can inline through them. I may expand on such things in a future blog post. What would also be greatly helpful to JIT implementers is to have some commitment to stabilizing the internal Ruby bytecode format, or at least, to not add extra complexity and special cases to existing bytecode instructions. Currently, CRuby implements 11 kinds of method dispatch, which, as you can imagine, makes optimization and inlining very challenging.
If you’re interested in contributing or simply trying YJIT, it is available on GitHub under the same license as CRuby. The caveat of course is that we are at an early stage in this project and it’s very possible that you could run into bugs, or that you may not find the current performance particularly impressive. If you do want to help, YJIT could use more testing. Tracking down small regression tests for bugs is very valuable to us. We could also use more, larger benchmarks that better reflect real-world Ruby usage.






