
Two months ago, I wrote about NoiseCraft, the visual programming language slash modular synth that runs in a browser that I’ve been working on in my spare time. This is very much a passion project, but what I’m hoping to achieve with this is to build a small online community for the exchange of synth patches and musical ideas, and to learn a lot more about sound synthesis in the project.
Since the announcement, the project went on to get over 520 stars on GitHub, the app got over 66,000 hits and 155 new users registered accounts at noisecraft.app. The first thing I noticed is that the number of people who created accounts is much larger than the number of people who shared projects through the app. Maybe that’s just because are too shy to share what they’ve working on. Maybe it’s because I gave people the option to save projects to local files. Regardless, I’m going to keep that option because I think people like the option of being able to own their own project files, to own their data so to speak.
The project made it to Hacker News and I would say the reception to the project was generally good. I was very happy to see all the cool projects that were shared, but I was a bit disappointed to see that the project attracted only a few open source contributions. Multiple people complained that the user interface didn’t behave like their favorite graph editor and suggested I should go try out <paid-commercial-product-i’ve-hever-heard-of> for inspiration, but few people volunteered to pitch in and help. Some of the criticism was definitely valid and helpful, but I have to say, it’s kind of hard running an open source project and after months of work, receiving mostly negative feedback. A lot of people are eager to criticize, but few people take the time to give positive feedback when things work well.
Here’s some of my favorites among the projects people have shared:
- Dialing in 2: noisecraft.app/179
- (a or not b)’s Drum Machine: noisecraft.app/203
- Dreamy glimmer: noisecraft.app/130
- Happy Sines Dance With My Saw On Five Bars: noisecraft.app/220
- Tekno 2: noisecraft.app/140
- Swing Pringle: noisecraft.app/115
In the last two months, I’ve made various incremental improvements to the app. I improved the help page, fixed a number of bugs, made ergonomic improvements to the UI, added a featured section on the browse page, implemented some new node types, and most importantly, got NoiseCraft to work on Firefox. The situation is unfortunately not as good on Safari. With some help from open source contributors, we found that there were at least 3 problems preventing NoiseCraft from working well there. Among other things, Safari’s pointer capture API is broken. This API is several years old at this point and very commonly used, which makes it hard to understand why these obvious problems haven’t been fixed. Safari doesn’t have a public bug tracker that I’m aware of, which makes it hard to even report problems like these.
In terms of upcoming new features, I’ve been making incremental progress towards adding the ability to group multiple nodes into user-created modules. I think that will open up many interesting possibilities. Among other things, I’d love to be able to easily create something like a drum machine in NoiseCraft, with modules corresponding to different sounds or sound effects, which can easily be reused in new projects.
When it comes to attracting new users, I haven’t been aggressively promoting NoiseCraft because there’s always the sense that more could be done to make the app better, and there’s a limit to how much free time I can spend on the project. However, I’ve been thinking that I might, in the next couple of months, create a small beat making contest with a small prize for the best entry.
If you think NoiseCraft is cool and would like to contribute, there’s a number of issues on GitHub marked with the help wanted tag. I’m also very curious to see what you can create with the app :)

One of the most frustrating experiences, both as an end user and as a programmer, is to try to run a piece of software that used to work perfectly not that long ago, only to find out that it’s now broken, the software won’t run anymore, and it’s not clear why. The software didn’t change, but something broke, seemingly for no reason. This is often due to the phenomenon known as “code rot”, or “bit rot”.
I used to work in a deep learning research lab, and I’ve seen cases where researchers had published code just six months ago, but one or more of the dependencies on which they relied had since made breaking changes. That put us in the unfortunate position of having to troubleshoot someone else’s code. Sometimes you were lucky, and the problem was just that one of the Python packages which their code needed had made breaking changes, and the problem could be fixed by simply editing the project manifest. Sometimes people imported packages which they didn’t really use, and we could completely remove the dependency. Other times we had to resolve conflicts between the multiple Python package managers that could be installed on a given system (pip2, pip3, Conda, and Ubuntu’s apt).
Editing a list of dependencies or wrangling with package managers doesn’t sound too bad, but PyTorch, the deep learning framework which was key to a lot of this work, had this irritating feature that each release needed a specific version of the Nvidia GPU driver to run. Installing an older GPU driver required root access, which we often didn’t have when working on remote compute clusters. Even if you were doing this on a local machine where you did have root access, the process of installing a new GPU driver was quite slow and tedious. Thanks to Nvidia’s unfriendly driver installers, this process couldn’t be automated, and once you were done, you might succeed in getting a specific release of PyTorch to work, but your other projects couldn’t run anymore, because they needed the latest release instead.
Researchers are encouraged to publish their code for the sake of replicability, but there’s not much point if nobody else is able to run said code a few months down the line. As such, we started to encourage those wishing to publish their code to rely on containerization using either Docker or Singularity. That fixed issues such as broken Python packages, incompatible versions of PyTorch or TensorFlow and missing libraries on the host system. However, there was another problem, which is that much deep learning code can’t really run fast enough on a CPU alone to be usable. Most of the code we saw required GPU acceleration. The solution to enable that was to use nvidia-docker, a special version of Docker which allowed code access to the host’s Nvidia GPU drivers. This, however, reintroduced the problem that the code running inside the container needed a special version of the GPU drivers to be installed on the host machine to run correctly. Nvidia’s solution to give people access to GPUs inside a Docker container was to breach the container and expose details of the host system in the process.
How much time do we collectively waste, every year, fixing bugs due to broken dependencies? How many millions of hours of productivity are lost every single day? How much time do we spend rewriting software that worked just fine before it was broken? In my opinion, code rot is a problem that we ought to try to fix, or at least alleviate. Because of fundamental reasons I’ll discuss later in this post, code rot probably can’t ever be fully eliminated, but I think the situation could be made a lot better through more principled and forward-thinking software engineering. At the very least, the situation would be improved if we acknowledged that code rot is a problem, and understood what causes it to happen in the first place.
How can we avoid code breakage? Linus Torvalds seems to think that in general, when compiling software, it’s better to statically link libraries if you can, because very few shared libraries are actually version safe, and with dynamic linking, you’re always adding complexity and exposing yourself to the risk that the system your software is going to get installed on won’t have a compatible version of the libraries you need.
In my opinion, for software that relies on a package manager, it’s better to fix package version numbers if possible. That is, to specify directly in the manifest of your package which version of each dependency to use. The reason for this is that you unfortunately can’t trust newer version of your dependencies not to make breaking changes, and often, one broken dependency is all it takes to render your software broken. In some cases, programmers may avoid specifying fixed version numbers because package managers such as Python’s pip don’t support having multiple versions of a given package installed at the same time, which could mean that the version of a package you request could clash with other software already installed on a given system. This is a shortcoming that needs to be addressed by package manager if we want to build reliable software.
There’s another problem though. Part of Python’s appeal is that it makes it easy to link with C code through its Foreign Function Interface (FFI). This is part of what made Python so popular, because it makes it easy for anyone to write a package to interface with commonly available C libraries and benefit from the strength of the C ecosystem. However, this convenience comes at a cost. The FFI is essentially a trap door through which software gets access to external dependencies that can’t be controlled by the package manager, which vastly increases the risk of code breakage. Third party package managers such as Conda try to address this by managing the installation of external libraries as well as Python code, but this can potentially introduce conflicts with Python packages installed through other means.
In my opinion, the most practical solution to manage with these problems in the real world is to take a conservative and minimalistic approach to software design. Purposefully minimize dependencies if possible. Don’t add new dependencies unless the value added is really worth the added cost of potential code breakage down the line. Avoid external dependencies as much as it’s reasonable to do so, and when you do choose to rely on external packages and libraries, pick libraries that have a long history of being stable, well-maintained, backwards compatible and easy to install. Remember that it can take just one broken dependency for your software to fail to run on a user’s system, and if your software breaks, they might not even tell you it’s broken.
Good software engineering practices can go a long way towards minimizing the risk of code rot, but I think it’s also valuable to ask ourselves what is the cause of code rot in the first place. Could we possibly build software that doesn’t rot? One interesting observation is that such software does exist, in a sense. People still write software for retro gaming platforms such as the Super NES and the Atari 2600. These platforms are essentially frozen in time, with a fixed set of devices and limited I/O capabilities. The fixedness of the platform, its simplicity, and the impossibility of relying on external software packages means that any software you write for it is unlikely to be broken by changes in the platform itself.
The root cause of code rot is change. The world itself is changing, and so is software. As such, the only way to be completely protected from code rot is to target a platform that never changes. Not just the platform itself, but every interface the platform has to the outside, every device, file format and networking protocol. We can’t stop the world from changing, but we can try to build software on more stable foundations. Like San Francisco’s Millennium Tower, modern software is build on soft soil that keeps shifting under our feet, but it doesn’t have to be that way.
Although the world does change, many elements of the computing world remain fairly stable. Computer keyboards have been around since the 1950s. Color displays have been around since the 1980s. Touch devices have been commonplace for over a decade. IPv4 was introduced in 1981 and IPv6 in 1995. If I’m writing a program that only needs to read input from a keyboard and pointer device, and display pixels on a screen, there’s no real reason why that program ever needs to break. The APIs for getting input from a keyboard and rendering frames to a display can be extremely simple. The world will keep changing and new I/O devices will be invented, but even 200 years from now, the concept of a keyboard and a color display should be easy to understand and interface with.
Recently, I’ve been thinking about the design of virtual machines. If we want to create software that doesn’t break, maybe what we need is some kind of executable code archival format. A minimalistic virtual machine with a small set of I/O devices that are interfaced through a small API surface, a small RISC instruction set, and an overall design that’s generally kept as simple and stable as possible. Something like the modern equivalent of a Commodore 64, with a high-resolution color display and the performance of a modern machine. I don’t think something like that would be applicable for every use cases, but I surmise that much of the software we use only really needs to interface with the outside world in fairly simple ways. For example, it needs to get input from the user in terms of mouse clicks or touch devices, it needs to draw pixels to display a user interface, and it might also need to read and write files, and maybe access the network. That software doesn’t fundamentally need to link to any external libraries, everything can be statically linked, it just needs simple, stable interfaces to access the outside world.
The idea of a Virtual Machine (VM) isn’t new. The Java VM tried to achieve this but largely failed. Sun Microsystems coined the famous “write once, run anywhere” slogan, which people began to jokingly mock as “write once, debug everywhere”. In my opinion, the area where most VM designers go wrong is that they tend to expose too many APIs, and each of them has an API surface that is much too large. When an API has a large surface, it’s very easy for subtle bugs and corner cases to creep in. You almost inevitably end up with different implementations of the API behaving in different ways. The Web Audio and Canvas HTML APIs are good examples of this. APIs with a large surface are created because VM designers believe this is more convenient for programmers, and will yield better performance. However, this convenience has a cost, in that it makes code breakage much more likely. Fundamentally, to output audio, one should be able to output a simple list of floating-point samples, and to draw pixels, one should be able to output a grid of pixels. It doesn’t have to be much more complex than that, and if the APIs were kept simpler, they would be much less likely to break.
In order to minimize the risk of code breakage, API boundaries are not the only thing one has to think about. If your software interfaces with the outside world, you also need to think about file formats and networking protocols. In this area, choosing mature, stable, open standards is generally preferable. I don’t know if my idea of a code archival format, or a virtual machine designed for maximum API stability will see the light of day. For the moment, it remains a thought experiment, but in the meantime, I encourage every developer to think about purposefully minimizing dependencies, about designing smaller, more stable APIs and about packaging their software in a way that will maximize its useful shelf life. Engineering more robust and durable software is one way in which you can improve the lives of a large number of people in small ways and help reduce electronic waste.

I’ve seen multiple discussions online as to the negative effects of the internet on society. There’s definitely harmful content online. It makes me sad to see the internet being used as a tool to spread anger and hate, and to further the political divide, but today I’m going to share a personal story about how, in the late 90s and early 2000s, the internet changed my life.
When I was a kid, my mother worked as a journalist. She would often bring me to book launches and events of the sort. I distinctly remember being offered Perrier water to drink and hating it (how could anyone drink this?), and being bored out of my mind. Book launches were one of the worst places you could possibly bring a kid, but she often didn’t have a choice, being a single mom with no father in the picture. She was well connected and had a wide circle of friends. Her income was modest but we were doing alright. We lived in a fairly roomy two bedroom apartment in a co-op smack in the middle of downtown Montreal.
Unfortunately, things took a turn for the worse. My mother started to complain about the neighbors being too loud. Just a little at first, but eventually, it became quite obsessive. She was complaining but I never heard any noise. At first, I couldn’t understand what was going on or why she was so upset. It turns out these were just early symptoms of the development of her mental illness. Over the course of two painful years, she lost it all: the job, the connections, the friends, the apartment, the little savings that she had. Even her own sister decided to cut contact with her.
Fast forward to the start of high school, I was 12 years old, and my mother was working as a cook. Unfortunately, even though she was way overqualified for that job, she lost it too, and we ended up on welfare, living in a much smaller apartment with no windows in the living room, and a black mold problem. On a social level, things weren’t going too well for me either. The other kids at school would pick on me and I’d often get into physical fights. I got suspended twice and was nearly kicked out of school. I can’t say for sure why I got into trouble so much more than my peers. Part of it was probably just that I was a nerdy kid, and teenagers are assholes, but another part of the problem is likely the belief system I grew up with. My only parent would repeatedly tell me that the world was full of bad people who are out to get you and can never be trusted. Being raised with that kind of belief system doesn’t exactly help you make friends.
Sometimes, I’d get home from school and my mother seemed to be doing alright that day. I’d settle down, sit at my desk and get started on homework, but then I’d suddenly jump, surprised by a loud shriek. My mother would suddenly become angry, and loudly shout back insults at the voices in her head. She was subject to extreme, unpredictable mood swings. One moment she’d be kind, the next she’d be angry. I tried to explain how disruptive and painful this was for me, but no amount of explaining seemed to help. I couldn’t find peace anywhere. Not at home, not at school, sometimes not even in my sleep. I felt truly alone.
After my first year of high school, the summer came. I had few friends, and the friends I did have were much wealthier than me. I didn’t have an allowance so I couldn’t ever go with them to shop, or to the movie theater or even to eat at a burger joint. I had to wear clothes purchased at the Salvation Army which mostly looked ok but other kids occasionally made fun of. I felt like living in poverty contributed further to my isolation. I spent most of that summer alone. I’d get out of bed and just lie on the couch, feeling bored out of my mind, with no energy to do anything. My mom became worried about how apathetic I’d become and took me to see a doctor. We did some blood tests, and everything came back normal. Looking back on it, I think what I was experiencing was a major depressive episode. I was still just a kid, and I had hit rock bottom.
I was very interested in computers, but our aging 386 PC had just died, which contributed to my feelings of despair. We were poor, but as tortured and dysfunctional as she had become, my mother still deeply cared about me and always did the best that she could to be a good parent. She knew I loved computers, and she knew they were useful for school work, so she took some of the little money that was left in her retirement account and bought us a brand new Pentium computer. We couldn’t afford any software for it, but that was a solvable problem.
Around the same time, my best friend got internet access at home through AOL. He was nice enough to share his access information with me and I started logging in through his account. I was instantly hooked. There was so much content, so much to read, chat rooms with so many people to talk to. Soon enough, I got an angry phone call from my friend. I’d used up his 100 hours of monthly internet access and his access was cut out until the next billing period. Oops.
I started doing the leg work of convincing my mom that we should get our own unlimited internet access subscription. The cost was 28 dollars a month, which, out of the $800-900 welfare cheque she was getting, was a lot of money. I told her this would be very useful for school, we’d have access to so much information, and I could play video games online, I’d finally have something to do. It took a lot of convincing, but I think she saw how passionate I was about the whole thing, and she eventually accepted.
In 1998, I got internet access at home, and I feel like this was a genuine turning point in my life. From that point on, my life started to gradually improve. It wasn’t all uphill, there were lots of ups and downs, but I was never bored again. There was always something to read, something to learn. I could play video games online and quickly started making online friends. My feelings of loneliness were alleviated because I always had people to talk to. English was my second language, but I became almost fluent very quickly. As silly as it might sound, through online chats and by making friends online, I also started to develop some much needed social skills and a better idea of what normal, healthy human interactions could look like.

I’m not sure how old I was exactly, but not that long after I got internet access, I decided to do some online searches about mental illness. I found a webpage that described the symptoms my mom had. She was a textbook case of paranoid schizophrenia. She matched the description perfectly. I took it upon myself to have a conversation with her and try to explain, as gently as I could, that she needed to go see a psychiatrist to get some help, for both of our sakes. Unfortunately, that conversation went about as poorly as you can imagine. She got extremely angry, screamed at me, and locked herself in her bedroom. In her world, it wasn’t her that was crazy, it was everyone else.
I was at my wits’ end and I thought about reporting myself to child protection services, but a few days later, on the evening news, I heard a story about children in foster homes being molested for years and living in horribly abusive conditions. I made the cold calculation that as painful as my life was, it was probably better than rolling the dice with the child protection services. I had food, shelter, clothing, access to a decent education, and most importantly, internet access. Devil you know, devil you don’t. I realized that the only way forward was stoicism and hard work. I’d need to succeed in life so that I could be independent.
Through the internet, I learned various computer maintenance skills, eventually buying new hardware and upgrading our home computer. I started to learn about programming. I connected with a guy who went by the nickname SteveR, a tech professional who became my friend slash mentor, and answered many of the questions I had about C++ programming and video game development. My passion for computers, technology, and all the things I could learn about and people I could meet online are a big part of what kept me going. I always had something positive to focus on and fill my time with.
Fast forward a few years, around the time I was 15, and I was running a side-hustle of sorts. I’d learned enough IT skills that I was starting to become a competent computer technician. My friend’s parents were paying me $20 an hour to do tasks such as hardware upgrades, installing newer versions of Windows, backups, installing wifi routers and troubleshooting various problems. I didn’t have a car, so they’d either come pick me up or bring their computers to our apartment. I often got to keep the spare parts after computer upgrades, which I’d either use to upgrade my own machine or go trade at the nearby computer store. I bartered my 14” monitor and a graphics card for a 17” monitor. I don’t know how realistic it would be to do that today, you certainly couldn’t barter computer hardware at Best Buy, but I think the store owner had a soft spot for me, he respected the hustle.
As soon as I reached age 16 and was legally old enough to be employed, I decided to look for a part-time job. My mom suggested that I should drop off my CV at the local computer store. I thought that was a bit silly (who would hire a 16 year old for this?), and I felt even more silly when, after dropping off my CV, the owner told me he wasn’t looking to hire anyone. However, a few weeks later, the next time I came by hoping to barter some parts, the owner said that he was now looking to hire someone, and I could have the job if I wanted it. I didn’t have an allowance, but it didn’t matter anymore. I earned my own money, and with that came a little bit of freedom and hope that I could build myself a better future.
We were never able to afford cable TV at home, but eventually, my mom grew tired of the phone line being constantly in use, which gave me good ammunition to argue that we should get high speed internet. We eventually got DSL and with that, I was able to download movies and TV shows. This gave me access to more entertainment, but also helped me become even more fluent in English, which I knew would be important for a career in technology.
As I progressed through high school, my mental state improved, but I still felt very lonely. What I lacked in terms of real-world interaction, I tried to make up for with online friendships. I spent some time hanging out on various IRC channels. One of the channels I hung out in was simply called #montreal. It was mostly an endless torrent of stupid jokes and shitposting, but one night, I noticed something strange. Among all the stupid comments, one message stood out. A woman had written “I’m about to kill myself and I’d like to talk to someone before I go, message me”. The other IRC users ignored her, and she repeated her message one more time. I messaged her. She explained how she felt lonely, alone and unloved. I told her that I very much could relate, and that whatever she wanted to say, I was there to listen. I tried to say nice things to her, to explain that things were probably not as hopeless as she thought, but it was no use. She said she had just swallowed a bunch of pills, and she quickly logged off.
It was a distress call, but she didn’t really want to hang around and talk. I didn’t have any information about her, not her name or her phone number or address, but when she had logged into the chat, the IRC server displayed her IP address. I felt very awkward and was afraid of not being taken seriously, but I dialled 911 and explained the situation to them. I gave them her IP address (which I had them repeat back to me), the name of her internet service provider and the time when she was logged on. I told them that if they called the ISP and they gave them the IP address and the time, the ISP would know her home address. The woman on the phone said that they would take it from there.
The next day, I had the TV on in the background and the evening news program was just starting. At the start of the bulletin, they gave a quick outline of the stories they were going to cover. Among those stories, the news anchor read something to the lines of “an internet user saves the life of a young woman in distress”. Then they cut for an ad break. I was very excited to hear the actual news story, but suddenly, my mother called out “dinner is ready!” and insisted that I come and sit down to eat. I got distracted, and I never did hear the full news story (ha!). Where is that woman now? How is she doing? Is she still alive? I’ll never know, but in that moment, I was able to be present, and to do something to help somebody else, and I felt proud of that. It gave me hope that I could make a positive difference in the world.
In high school, I was a B+ student at best. I was never particularly motivated, and most probably too (di)stressed to thrive, but by the time I made it to university, I’d been programming in C++ for three years and had a huge head start on everybody. I had gotten accepted into a computer science program at a local university, and I decided that since computers were my turf, I was going to show everyone what I could do by getting the best grades. I was going to beat everyone without getting into a fight. I completed my undergraduate degree with a 3.97/4.00 GPA. Out of 30 courses, I received 27 As and 3 A-minus grades.
I don’t want this to read like a story about how I overcame every obstacle alone and pulled myself up by bootstraps with no outside help. I struggled a lot along the way but the reality is that as challenging as my life situation was, as lonely and misunderstood as I felt at times, there was luck in my misfortune, and I did receive help. My mom was mentally ill, but despite this, she didn’t suffer from alcoholism or any other addiction. She was always able to cook, pay the bills, and perform the most basic functions a parent needs to do. The situation in my home was often very tense, but there was never physical violence. My mother, being university educated herself, cared about my education and genuinely wanted me to succeed. She invited me to keep living with her during my university studies to save money. I sure wanted to get the hell out of there, but it made financial sense to stay a little bit longer.
Right around the time that I was starting university, after a few years on a waiting list, we got access to a subsidized apartment with more sunlight and no mold. This apartment was a 30-minute walk away from the university which allowed me to get some exercise every day. Thanks to Canada’s low tuition costs, I was able to earn enough from summer jobs to pay for tuition and not have to work during the school year, which allowed me to better concentrate on my studies. The classmates I had who were forced to work during the school year understandably struggled with the heavy computer science curriculum.
On the internet, I was able to access resources about psychology and how to cope with trauma, which I also found helpful. YouTube became available in 2006, and through YouTube, I’ve watched many lectures from leading psychologists about depression, PTSD, meditation and many other interesting topics. I opened up about my suffering and received support and valuable advice from friends I’d met online. I’m not going to pretend that being your own DIY therapist is the key to better mental health. I was lucky, through my university, to get access to professional therapists at discounted rates, which helped me begin my own healing process.
This is part of the story of how the internet changed my life for the better. I’m an early millennial and I was raised online. Through the internet, I found friends, support, and the human connection that I was lacking in real life. I also found valuable information that helped me help myself and sometimes help others. The key with information is always to effectively filter the good from the bad, which is a genuine life skill unto itself. My life today isn’t perfect, but it’s better than it’s ever been. My message to all the people out there who are struggling is to believe in yourself. If you help yourself and you let others help you, things are never hopeless.

Like many of you I’m sure, I watched the TeslaBot announcement and felt that this presentation was premature. They didn’t even have plastic mockup of the robot to show, just some guy dancing in a costume. I’m very excited about the potential of general purpose robotics, but it seems like Elon Musk is once again underestimating the challenges in this problem space. Tesla’s Full Self Driving project is barely getting to the point where it might become useful, and now they’re going to attack a problem 100 times harder. Well, okay then.
That being said, as an investor in Tesla, I’m still excited about the project. Tesla is profitable and has 16 billions in cash on hand at this point, which means they can throw more money at the problem than individual company or research group ever has. The company also has their own lightweight, low power neural network accelerator, and they’ve successfully designed high efficiency motors and battery systems. Their extensive manufacturing expertise also means that, if they were to mass produce such a thing, they really could bring the cost down.
My own belief is that the only way to ever build general purpose robotics is to have engineers working on the problem. It’s one thing to have academics working on toy problems in simulation, but real-world robotics is where the rubber meets the road. In my opinion, there is great power in incremental improvements. The way to bring forth general purpose robotics is build robots that can perform some basic tasks in a narrow real-world domain, and then gradually extend their abilities and circle of competence. A lot can be achieved through trial and error, and iterating on a design to keep improving it.
Most engineers would probably tell you that building the Tesla bot, the physical component of it, is not the hard part. We know how to build the hardware, or at least, we can figure it out fairly quickly. The hard part is building the software that drives it. A general purpose humanoid robot will have to have a detailed understanding of the real world around it, and be able to handle many more special cases than a self driving car. Even the “simple” problem of teaching a robot how to reach and grasp teacup without spilling the tea or breaking the cup is a hard problem. Brewing the tea is even harder. Doing that in a house you’ve never visited before is harder than rocket science. So where does that leave us? Where do you start? What could you do with a Tesla bot?
In my opinion, there are simpler, easier, better defined problems to attack before you try and put a humanoid robot in a home or office environment. It so happens that Tesla is looking at building an automated network of so called robotaxis, the self-driving equivalent of Uber and Lyft. In order to build something like that, you’ll need a workforce to perform tasks like routinely cleaning both the inside and the outside of the self-driving cars. This is a simple, repetitive task that requires only limited communication, which makes it an ideal real-word use case for the first humanoid robots.
Tesla could build a Tesla car wash which would gradually expand into an automated robotaxi service station. The problem domain of cleaning the inside and outside of Tesla’s robotaxis is interesting because it’s both challenging but also fairly repetitive and predictable. You can perform the task with a limited number of basic tools, and it’s unlikely to put anyone’s life in danger. The environment in which the task is performed can be somewhat controlled and the tools can be standardized, but there’s also going to be an interesting amount of diversity in the scenarios encountered. Lastly, it should be fairly realistic to have humans provide a decent amount of demonstration data by remotely piloting the robot or through video footage.
This thought experiment has me optimistic that even though fully general purpose robotics could take another 20 years or more to materialize, it’s not impossible to think that something like a Tesla bot could start to become useful in less than 5 years. It’s a narrow problem domain, but it’s easy to think that you could start by having the robot wash the outside of the car, and then expand to having it clean the inside. You could start with just one model of car and then expand to more. You could gradually add new features such as inspecting cars for damage, charging cars, and eventually changing tires or even performing more advanced maintenance. You could even laterally expand to other similar domains such as cleaning Tesla’s cafeterias or factory floors.
This is a hard problem domain, but it’s not impossible to find a starting point that we can realistically tackle, and once the robots start to become useful, a virtuous cycle can begin. As Tesla begins to mass produce and iterate on the robot’s design, the cost can come down. This can allow academic partners and various startup to buy them at affordable prices and begin to do research of their own. The sophistication of the robot’s understanding of the world can improve, and its circle of competence can expand. The most important part is to get the ball rolling.

I’ve recently resumed work on a side-project I started back in 2019 to create a browser-based visual programming language for sound synthesis and music. I was initially hoping to make this a commercial SaaS product, but I got discouraged when I realized that running and promoting a business could easily become a second job on top of my full-time day job, and suck all the fun out of the project. Thankfully, about six months ago, my motivation to work on the project came back. I decided to build an improved version of this software and make it open source.
NoiseCraft is a node-based visual programming language, loosely inspired by Max/MSP and PureData. The main goal of this project is to provide a way for people to explore musical ideas, and to enable people to share these ideas easily. It’s designed to be easy to use and approachable for beginners. There’s only one type, every connection has a floating-point value that changes over time. It runs in a browser and uses the Web Audio and Web MIDI APIs. This means you don’t need to install anything, and you can share links to your projects just as easily as you can in Google Docs. The user interface is minimalistic and designed to be as simple as possible to facilitate learning. No cryptic shortcuts, no submenus, no esoteric terminology.
I want to set realistic expectations. This is something I’ve been working on in my spare time. It’s not trying to be Ableton Live or Reason. It’s definitely not perfect and you could run into bugs. It’s designed with desktop and laptop computers in mind. It might eventually work on tablets, but for the moment, it probably doesn’t (unless you connect a keyboard and mouse to your tablet). It’s been tested in Chrome and Edge. However, it doesn’t yet work in Firefox because we’re waiting for a bug to get fixed. It also doesn’t yet work in Safari. However, despite its limitations, NoiseCraft has many interesting features:
- Easy to use sequencer node with multiple patterns
- Audio is now rendered in a background thread to avoid glitches
- You can copy and paste, even between different browser tabs
- Colorful, curved edges that are easier to follow visually
- Undo and redo
- Projects can be shared in the cloud in a few clicks
- Projects can also be saved to local files to a simple JSON format
- Ability to play notes from MIDI keyboards and devices
- Ability to map virtual knobs to knobs/sliders/mod/pitch bend on MIDI devices
- New clock divider and sample-and-hold nodes
I started this project to improve my understanding of synths and sound synthesis. NoiseCraft is ideally suited to explore the possibilities of additive, subtractive and FM synthesis. Most nodes are simple building blocks with a low level of granularity so that it’s easy to understand how things work. By connecting oscillators, filters, delays and other basic components you can create your own synth or groovebox. I’ve linked some fun example projects below to showcase various possibilities:
- Detuned saw, sub osc, ping-pong echo & distortion
- Kaïser Clicker Clicker’s FM (FM synthesis example)
- Triple oscillator + delay + overdrive pedal (playable with a MIDI keyboard)
- The little acid machine that could (my attempt at an acid sound)
- Noise Machine / Relaxing Ocean Sounds
- Polyclocks v.1.0 (polyrhythm)
- Long Gate & Retrigger
- Da Wubs (dubstep style wub-wub)
- andyS’ DTMF synth
- (a or not b)’s subtractive synthesizer v1.0
Many more examples can be found on NoiseCraft’s browse page and some instructions are provided in the help page. With this project, I hope to create a community for the open sharing of musical ideas. If this is something that interests you, I’m also hoping to find skilled, like-minded collaborators to help me improve the software. I’ll keep gradually improving it on my own, but there’s a limit to what a single programmer can do in their spare time. NoiseCraft could use testing, bug fixes and various improvements. Constructive feedback as well as contributions to the help page and documentation are also welcome. If you report bugs, please try to provide details on how to reproduce the issue and please be kind. The project is available on GitHub :)
The 1980s and 1990s saw the genesis of Perl, Ruby, Python, PHP and JavaScript: interpreted, dynamically-typed programming languages which favored ease of use and flexibility over performance. In many ways, these programming languages are a product of the surrounding context. The 90s were the peak of the dot-com hype, and CPU clock speeds were still doubling roughly every 18 months. It looked like the growth was never going to end. You didn’t really have to try to make your software run fast, because computers were just going to get faster, and the problem would take care of itself. Today, things are a little different. We’re reaching the limit of current fabrication technologies, we can’t rely on single-core performance increases to solve our performance problems, and because of mobile devices and environmental concerns, we’re starting to realize that energy efficiency matters.
Last year, during the pandemic, I took a job at Shopify, a company that has a massive server infrastructure powered by Ruby on Rails. I joined a team with multiple software engineers working on improving the performance of Ruby code in a variety of ways, ranging from optimizing the CRuby interpreter and its garbage collector, to the implementation of TruffleRuby, an alternative Ruby implementation. Since then, I’ve been working with a small team of skilled engineers on YJIT, a new JIT compiler inside CRuby.
This project is important to Shopify and Ruby developers worldwide because speed is an underrated feature. There is already a JIT compiler inside CRuby, known as MJIT, which has been in the works for 3 years, and while it has delivered speedups on smaller benchmarks, it has, so far, been less successful at delivering real-world speedups on widely used Ruby applications including Rails. With YJIT, we take a data-driven approach, and focus specifically on performance hotspots of larger applications such as Rails and Shopify Core (Shopify’s main Rails monolith).
YJIT is an attempt to gradually build a JIT compiler inside CRuby such that more and more of the code is executed by the JIT, which will eventually replace the interpreter for most of the execution. Our compiler is based on Basic Block Versioning (BBV), a JIT compiler architecture I started developing during my PhD. I’ve given a talk about YJIT in March of this year at MoreVMs 2021 workshop if you’re curious to hear more about the approach we’re taking.
I don’t want to oversell YJIT. Our results have significantly improved since the MoreVMs talk, but are still modest. We’re very much at the early stages of this project and there are known bugs in our implementation. That being said, according to our benchmarks, we’ve been able to achieve speedups over the CRuby interpreter of 7% on railsbench, 19% on liquid template rendering, and 19% on activerecord. YJIT also delivers very fast warm up. It reaches near-peak performance after a single iteration of any benchmark, and performs at least as well as the interpreter on every benchmark, even on the first iteration.
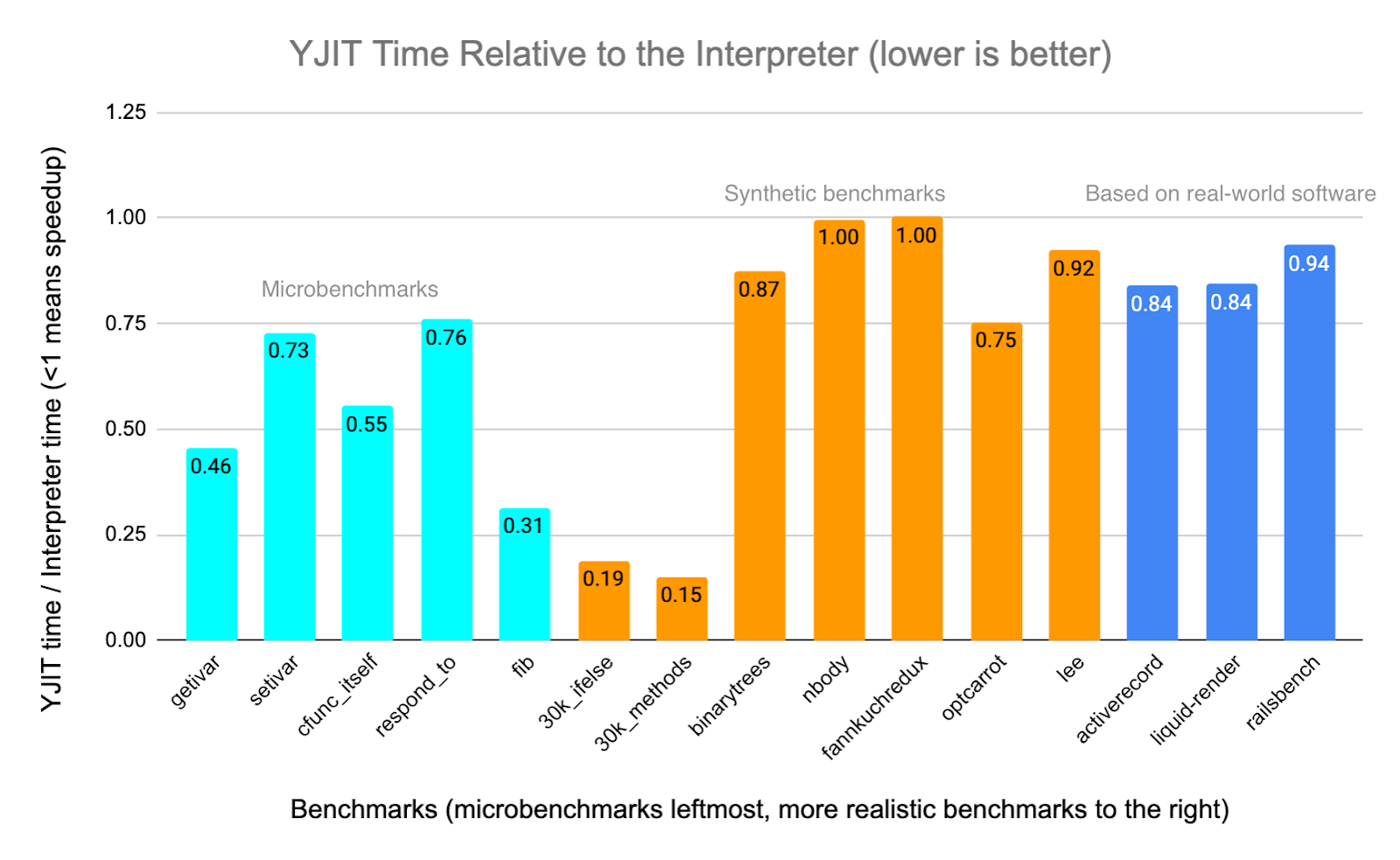
Building YJIT inside CRuby comes with a number of limitations. It means that our JIT compiler has to be written in C, and that we have to live with design decisions in the CRuby codebase that were not made with a high performance JIT compiler in mind. However, it has the key advantage that YJIT is able to maintain almost 100% compatibility. We are able to pass the CRuby test suite, comprising about 30,000 tests, and we have also been able to pass all of the tests of the Shopify Core CI, a codebase that comprises over 3 million lines of code and depends (directly and indirectly) on over 500 Ruby gems, as well as all the tests in the CI for GitHub’s backend.
We believe that the BBV architecture that powers YJIT offers some key advantages when it comes to compiling dynamically-typed code, and that having end-to-end control over the full code generation pipeline will allow us to go farther than what is possible with the current architecture of MJIT, which is based on GCC. Notably, YJIT can quickly specialize code based on type information and patch code at run time based on the run-time behavior of programs.
Currently, only about 50% of instructions in railsbench are executed by YJIT, and the rest run in the interpreter, meaning that there is still a lot we can do to improve upon our current results. There is a clear path forward and we believe YJIT can deliver much better performance than it does now. However, as part of building YJIT, we’ve had to dig through the implementation of CRuby so we could understand it in detail. In doing so, it’s become obvious that one of the main performance challenges in implementing a fast JIT compiler in CRuby, is that key elements of the architecture are optimized with an interpreter in mind, and not a JIT compiler.
For instance, in CRuby every object instance variable read or write requires multiple pointer indirections and dynamic checks. In order to read an instance variable (ivar) from a Ruby object, one has to:
- Check that the receiver is a not an immediate value
- Check that the receiver is not Qnil
- Check that the receiver is a T_OBJECT
- Check that the object class matches our inline cache
- Read the serial number from the class (extra pointer indirection, memory access)
- Check whether the object stores its ivars internally or on an external table
- Potentially: read the pointer to the external table (extra memory access)
- Potentially: check if the ivar index is within the bounds of the external table
- Read the ivar from the object or external table
Note that at the moment, only 3 instance variable slots can be stored directly on the object itself, so instance variables are almost always on an external table in the vast majority of accesses.
As you can imagine, even though some of these checks can sometimes be optimized away, generating efficient machine code for instance variable accesses in CRuby is very difficult. It doesn’t have to be this way. This problem was solved by Self, the successor of Smalltalk, in the early 1990s. Self used what they call “maps”, but nowadays are typically referred to as object shapes (see Section 3 of An Efficient Implementation of SELF). This is tested and proven technology, used by Chrome’s V8 , Firefox’s SpiderMonkey, and TruffleRuby. If you are curious, this excellent blog post by Mathias Bynens and this great talk by Benedikt Meurer explain the concept of object shapes and shape trees in more details.
# Optimized ivar reads can be as short as three x86 instructions
# ebx = pointer to the object
cmp [ebx + <object shape offset>], <cached object shape>
jne <inline cache miss>
mov eax,[ebx, <cached ivar offset>] # load the ivar value
Thanks to object shapes, V8, SpiderMonkey and TruffleRuby are able to implement instance variable reads in as little as one single dynamic check, giving them an enormous performance advantage. We believe that with a coordinated effort that involves the Ruby Core developers, key technologies such as this could be implemented inside CRuby, and would benefit MJIT, YJIT, and any other future attempts to implement a JIT inside CRuby, and this without significantly impacting the performance of the interpreter.
Matz has stated in his recent talk at Euruko 2021 that Ruby would remain conservative with language additions in the near future. We believe that this is a wise decision as rapid language changes can make it difficult for JIT implementations to get off the ground and stay up to date. It makes some sense, in our opinion, for Ruby to focus on internal changes that will make the language more robust and deliver competitive performance in the future.
I believe that, through incremental, targeted changes, CRuby can be gradually re-engineered so that it can eventually have a true high-performance JIT compiler. Doing so must necessarily involve both JIT compiler experts and the Ruby Core developers. One key area of potential improvement would be the inclusion of object shapes. There are other things that could help us, such as rewriting some C methods in pure Ruby, such as Array#each and Fixnum#times, so that JIT compilers can inline through them. I may expand on such things in a future blog post. What would also be greatly helpful to JIT implementers is to have some commitment to stabilizing the internal Ruby bytecode format, or at least, to not add extra complexity and special cases to existing bytecode instructions. Currently, CRuby implements 11 kinds of method dispatch, which, as you can imagine, makes optimization and inlining very challenging.
If you’re interested in contributing or simply trying YJIT, it is available on GitHub under the same license as CRuby. The caveat of course is that we are at an early stage in this project and it’s very possible that you could run into bugs, or that you may not find the current performance particularly impressive. If you do want to help, YJIT could use more testing. Tracking down small regression tests for bugs is very valuable to us. We could also use more, larger benchmarks that better reflect real-world Ruby usage.

I first started trading on the stock market back in 2016. I had been curious about stock trading before that, but up until that point, I did what most people my age did, which is to simply put money into a regular savings account without really thinking about it. Things changed when I took a job at Apple in Silicon Valley. Part of the compensation was in Apple stock, and so, my new employer opened a stock brokerage account in my name where the shares would be deposited every six months. All of a sudden, I had access to a website where I could log in and place trades, and a whole new world was opened to me. I could own a small piece of some the greatest companies in the world, and that seemed really exciting, but which ones should I buy, and how much? What strategy should I use? I did what any responsible adult would do, and turned to YouTube and Reddit to look for answers.
This probably sounds laughable to many of you. I’m sure it would sound laughable to most Wall Street professionals, but there’s a lot of valuable information out there on YouTube, Reddit and other social media platforms. The key is knowing how to filter out valuable insight from terrible advice. Furthermore, investing fundamentally a social phenomenon, and as the GameStop saga made clear, social media is changing the game. Suddenly, ordinary folks with a computer or cellphone have access to an incredible amount of information, and huge online communities where they can exchange ideas. This is levelling the playing field to some extent.
That’s not to say that there isn’t anything dodgy happening on these platforms. I follow multiple YouTubers who post videos about stocks, and I noticed something both interesting and frightening. A YouTuber I won’t name, with over 600,000 followers, would often post videos where he would praise some specific stock. Often these stocks had relatively small market caps, about one billion dollars. Without fail, in the day following his videos being posted, the price of the stock discussed the day before would raise by something between 10 and 30%. This guy, simply by having a large online following, could easily manipulate the market in real time. The potential for abuse there is obviously enormous. Sven Carlin, another YouTuber I follow, revealed that he and many others had been offered money to promote certain stocks. This kind of scam is nothing new, I’m sure that Wall Street stock analysts have been paid to promote stocks for as long as there have been stock analysts, but again, social media is changing the game. People you assume to be trustworthy regular folks just sharing their personal opinion might actually be paid shills, it’s just much harder to tell because they’re not wearing suits.
Why is it that the stock price of some companies, like Amazon or Tesla, seems to rise exponentially? It’s because investing is fundamentally a social phenomenon. Investing is about trust, and the stock price of a company reflects our collective belief in the future potential of that company to succeed and grow. For many years, the stock price of Amazon didn’t move very much. People questioned their ability to succeed, and the fact that they weren’t profitable, but some time around 2010, that view shifted very rapidly, as if some threshold had been reached. The idea that Amazon was going to succeed, that it was an unstoppable behemoth, became the dominant one seemingly overnight, and from that point on, the price of its stock never stopped rising. The same thing seems to be happening with Tesla. The company’s stock price has risen about 700% during 2020, and I don’t think that a rapid fundamental shift in the underlying business explains that. Rather, I think the rapid fundamental shift has been in the public perception of the company’s ability to deliver on its promises. That shift has been caused, in large part, by a large online community of unrelenting fans praising the company on social media. With social media, anyone can have a voice, it becomes possible for individuals to shift collective beliefs, and in doing so, we can make companies succeed or fail, and to some extent, reshape the future.

Investing is, or should be, about allocating capital to ideas you believe in, and it can be a beautiful thing, a force for change. Back in 2016, I started investing in multiple companies in the renewable energy space. I chose to do that because I was part of a growing online community of investors that believe in the potential of renewable energy, and its necessity for a better future. What I’ve been seeing, since then, is that as Tesla succeeds, more and more capital is flowing away from oil stocks and into renewable energy stocks. Starting in December 2019, before everyone was broadly aware of the pandemic, the price of oil giant Exxon Mobil took a sharp drop, while the price of Tesla started increasing steeply. Tesla has shown that renewable energy companies can succeed, and the rising tide lifts all boats. There’s more to it than just the stock price going up though. Like I said, the stock price, or more accurately, the total valuation of a company, reflects our collective belief that a company can succeed.
When a company’s stock price goes up, it suddenly becomes very easy for that company to raise money by selling more shares. This means there’s never been a better time to start a renewable energy company, because it’s easy to raise money to make that company grow. In some ways, it’s a self-fulfilling prophecy. Because we believe that green energy stocks can succeed, people buy the stock and their stock price goes up. Because people are buying green energy stocks, these companies can raise money easily. Since they can raise money easily, it’s much easier for them to grow, and to succeed, which also leads to a higher stock price. In many ways, our collective belief that these companies can succeed is making it possible for them to succeed. Are electric vehicle and green energy stocks in a bubble? Maybe, but it shouldn’t matter. Among these companies, those with competent management teams have already taken advantage of the current climate to raise money, and give themselves enough runway, even if there is a temporary pullback. Some of these companies will undoubtedly succeed, and the market will reward them for it. Don’t believe me, just watch.

John Carmack gave a great talk in which he explains why, before spending time working on an idea, he spends time trying to poke holes into it. Sometimes, it’s easy to get overly excited about an idea and get carried away. However, it could turn out that this idea has some fatal flaw, and if that’s the case, it’s probably be best if we can find that fatal flaw early, before spending hours, days or even weeks and months trying to implement a solution that was ultimately doomed to fail. There is wisdom in examining your ideas with an adversarial lens.
On the flip side, sometimes you have a problem that you need to solve, and you know it should be possible to solve it, because there’s no fundamental reason why the problem can’t be solved. I would say it’s been my experience that many people are often too quick to say that something can’t be done and dismiss all possible solutions you might suggest without doing due diligence. There’s often someone who will give you 100 reasons why your idea can’t work, and often, these people just lack imagination.
One example that has been on my mind recently is that of electric cars. Multiple jurisdictions have set the ambitious goal of completely ban the sale of gasoline-powered cars by 2035. Many Electric Vehicles (EV) advocates including myself believe that electric vehicles make up be the majority of new cars sold by 2030. Yet if you read discussions online, some vocal individuals will tell you that this is impossible. They will give you many reasons why electric vehicles can’t succeed, including range, a higher price tag, and that people living in apartments have nowhere to charge their vehicles. I would say that these people clearly lack imagination, and they’re failing to understand that reality is not static, it evolves over time as we adapt the world to our needs.
As technology progresses, the range and charging speed of electric vehicles keeps improving. As adoption increases, the price tag keeps coming down, and the amount of investment into EVs increases as well. I don’t live in a house, so I don’t have a garage, but at the last meeting of my condo association, the issue of installing EV chargers was brought up. This year, it should be possible for everyone who wants a charger installed to pay to add one at their parking spot. What about people who have to park their car on the street, you ask? You couldn’t possibly put a charger at every parking spot? Well, what if you could? Siemens is working on converting lamp posts into EV chargers. If you thought that charging on the street was an insurmountable technical obstacle, I say you lack imagination.
In 2020, Norway became the first country in which EVs took the majority of the new car market, with 54% of new vehicles sold being electric. You can argue that it’s easy for them, because they are wealthier than the rest of the world, but the reality is that electric vehicles are already coming down in price. There’s now a lot of competition, and Tesla has reiterated plans to produce a 25,000$ EV within a few years, with mass production inevitably bringing down costs.
The bottom line is, if there’s a problem that is really worth solving, trying to poke holes into potential solutions so you can dismiss them as quickly as possible isn’t always the right approach. You should do due diligence and give each potential solution a fair assessment, because you could also be shooting down ideas that would actually work. You should also ask yourself how you might actually go about overcoming the difficult obstacles that seem stand in the way, because some seemingly difficult obstacles might not turn out to be real issues in practice. The challenge to bring that idea into reality then becomes how to find a feasible path to your goal, and how to optimize and shorten that path as much as possible. Envisioning that path takes patience and some measure of imagination.
I strongly believe that in order to innovate, it’s important to be able to play with ideas. When you’re attacking a problem, it’s useful to be able to brainstorm, come up with multiple alternative solutions, and weigh the pros and cons. It’s also useful, in order to weigh the pros and cons, to try and imagine how a hypothetical solution can be integrated into an existing system, or how it could be extended, and what possible problems might arise.
It’s also very hard to innovate, to do something really new. Let’s face it, the total world population close to reaching almost 8 billion people. In every field, there is competition on all sides. Whatever you’re working on, there are likely other people working on it as well. Maybe someone else has already tried what you’re thinking of doing. It’s hard to stay relevant. If we just think about movie storylines, it almost seems as though every theme has been explored, and we’re just being fed the same clichés over and over again. Why even bother?
You Can Do It Better
I think the first thing to remember is that while a lot of ideas have already been thought of, many of them haven’t really been implemented properly. There are a lot of ideas that have been explored before, but poorly implemented. Coming up with an idea is the easy part, good execution is much harder. Most people give up without even trying. Some give up after they reach the first real technical obstacle. If you truly believe in the potential of an idea, you can separate yourself from the pack by going farther than the others who previously gave up.
Back in 2002, young Elon Musk founded SpaceX, with the goal of perfecting reusable rockets and sending people to Mars. Many people laughed at him. He had made a few millions with Paypal, but only an arrogant and narcissistic Silicon Valley entrepreneur could possibly imagine that he could launch a rocket company and take on established players like Boeing and Lockheed Martin. Yet, here we are, 18 years later, SpaceX has perfected reusable rocket boosters that can land themselves, they’ve sent astronauts to the ISS, they own most of the satellite launch market, and they’re now working on a fully reusable rocket.
SpaceX weren’t the first to work on reusable rockets. The idea wasn’t remotely new. The earliest concepts date back to the 1960s and there were many abandoned or failed projects. The competition was out there. There were a few multi-billion dollar companies already building rockets. If you’d asked me back in 2002, I would probably have said that Elon Musk had near-zero chance of succeeding. How did SpaceX manage to win? Probably, in part, because the existing players were overly comfortable. They had been fed secure government funding for decades. Why try to reinvent rockets when you can just keep doing the same thing and charge several hundreds of millions of dollars per launch? SpaceX won by executing an innovative vision to reduce cost with unwavering discipline. They went farther than everyone else, and built something much better.
On a smaller scale, if you’re an app developer, for example, you might be able to innovate over your competition by building an app with a simpler or more intuitive user interface. Maybe your app does nothing more than the others in terms of functionality, but it’s much easier to use. Your UI doesn’t require a user manual, users can figure out what to do quickly, and you reduce friction in a way that leads people to adopt your software.
Context Changes
The second thing you should know about ideas and innovation is that the world is always changing. It’s not the same place that it was 30, 20 or even 5 years ago. That makes it worthwhile to re-explore old ideas and adapt them to the modern context. In fact, there is this commonly known concept of the right idea at the wrong time.
There is a great documentary on a company called General Magic, who tried to build a smartphone with a touch screen too soon, before the technology was ready, and with poor, unfocused execution. There is also the story of the Apple Newton, which was also a flop. Many people knew that there was a clear future for Personal Digital Assistants (PDAs), but believing wasn’t enough, to make an idea come true, you need both good execution and an appropriate context.
Context is always changing. Sometimes very rapidly. Hardware becomes cheaper and better. The internet of 2020 is not the same as the internet of 1998 or even that of 2015. The people of today are different from the people of 10 or 20 years ago. You yourself are also changing and learning new things. Sometimes it’s worth re-examining old ideas. It’s not because others tried and failed that something is inherently impossible. Maybe they didn’t have the right skillset. Maybe they just weren’t in the right time, place or mindset.
Iterative Refinement
If there’s one thing you should believe in, as a software developer or as an engineer, it’s in the tremendous power of iterative refinement. You should believe in your own ability to learn from mistakes, be they your own mistakes or those of others, and refine a concept over time. By testing a machine again and again, you can identify flaws, and eliminate them, one at a time. You can go from a system that is broken and unusable to one that is fast and reliable. You don’t have to be fast, you don’t have to burn yourself out, you just need to keep at it.
Sometimes it feels like we take two steps forward and one step back. I think that in the software industry, it helps to spend time building a solid suite of tests to avoid regressions. The most important ingredient though, in order to keep refining a solution, is strong belief in the final vision that we are ultimately trying to reach.
Conclusion
The most important strength that you have is your belief in your own ability to learn and succeed. You also need to be able to filter out good ideas from bad ones, and to judge whether the context is right or not. Sometimes though, you also have to find a way to quiet your inner critic, the pessimistic voice inside yourself that is deeply afraid of failure. It’s easy to come up with 1000 reasons why some idea might fail, but you’ll never know if you don’t give it a proper shot, and the best way to learn is by doing.
With the current ongoing pandemic, it’s very easy to be pessimistic right now. We’re lonely, isolated, and it’s easy to despair, to believe that the world is going to shit. That we’ll never leave this behind. However, multiple vaccines are completing human trials with positive results. Tens of millions of doses have already been fabricated, with billions more to be produced in 2021. Vaccination is already underway in some countries, and set to begin in the US in about two weeks, and in Canada starting in January. It might feel hopeless right now, but there is light at the end of the tunnel. I choose to believe in human ingenuity.

My employer was kind enough to provide me with a top of the line MacBook Pro. It’s a beautiful machine with 6 CPU cores, 32GB of RAM and a 4K display, the most powerful laptop I’ve ever owned and a valuable tool in working from home. However, unfortunately, the slick machine suffers from a number of software problems.
For one, you can charge it using any of the 4 USB-C ports, but you really should only ever charge it from the right side. Another issue I frequently run into is that I have an external monitor, and despite configuring this as my primary display, the dock will randomly jump back to the MacBook’s monitor, until I go into the settings and move the dock to the right, and to the bottom again, at which point it goes back to the external monitor, until the next time it decides to randomly jump ship. A third issue is that whenever I reboot, it stays stuck early in the boot process, displaying the white Apple logo, and does nothing. It doesn’t complete the boot process until I unplug my USB-C devices. There are more problems, I could go on.
Apple isn’t the only one with these kinds of quality assurance problems. I recently installed Windows 8 on an older desktop computer I wanted to give to my mother (she unfortunately couldn’t see herself using Linux). The first thing I did after installing the new OS was to try and run Windows Update. However, it didn’t work, and I was appalled to find that on this version of the OS, Windows Update is broken out of the box. I learned that there was a patch to fix the issue, but the patch didn’t work, it displayed a progress bar that remained perpetually frozen. Online searches revealed that in order to get the patch to work, I had to unplug the ethernet cable.
Why is it that we live in a world riddled with bugs? I think there are a few reasons for this. No doubt, part of the issue is that our competitive capitalist economy makes major software and hardware vendors want to move at breakneck speeds. Technological progress doesn’t nearly justify a new generation of smartphones being released each year, but, fuck the environment, a new product needs to be released in order to maintain interest and keep sales numbers high. We move fast, and in the process, we break things.
I’ve been a user of Ubuntu Linux for over 10 years now. I chose this distribution because, at the time, it was the most popular, and that made it easy to find software, as well as online help if anything ever went wrong. Originally, when I discovered Ubuntu, it used the GNOME desktop, and things worked fairly seamlessly. However, around 2011, Ubuntu began shipping with a different user interface which they called Unity. This new user interface was riddled with bugs, and the reception was horrible. My understanding is that this user interface change cost Ubuntu its spot as the #1 most popular Linux distribution, where it was replaced by Mint, and now MX Linux.
Why did Canonical choose to replace GNOME in the first place? Probably because the first iPad was released in 2010, and at the time, people couldn’t stop talking about how tablet computers were the future. Canonical wanted to capitalize on the latest trend and make Ubuntu more appealing to tablet users. This necessitated a UI redesign with large buttons, something that looked more like iOS. In the process, they seemingly forgot that at the time, there were no tablets to run Ubuntu on, introduced many new bugs, and quickly alienated their existing user base, overwhelmingly running Ubuntu on laptops and desktops.

As of 2020, Ubuntu is back to running GNOME, and the most innovative feature to have been introduced to tablet computers is a detachable external keyboard, effectively turning said tablets into laptops. I don’t want to sound cynical and overly conservative. I love building new things, and I think that reinventing the wheel can be a valuable learning experience, but it seems obvious to me that sometimes, there’s a lot of value in stability and predictability. Some things should be reinvented, but in other cases, things don’t really need to change. We badly need electric cars and green energy, but maybe we don’t need that user interface redesign.
In software and hardware design, the things that we should be the most wary about breaking, are the interfaces that people rely on. APIs are an obvious area where stability is particularly valuable, and backward compatibility is crucial. Linus Torvalds is known to have vehemently defended a policy that the Linux kernel should never break user space. This policy makes sense, considering that the interface that the kernel exposes to software is one of the most basic and foundational APIs there is. If the kernel routinely breaks programs and libraries, that makes it very difficult to build anything on the platform.
It’s not just APIs though, it’s also programming languages. Many languages add new features all the time, and in the process, break existing software. It’s hard to build something when the ground is constantly shifting. Companies large and small, as well as individual developers, spend a huge amount of effort simply reacting to change and fixing what was broken. This has made me think that, when developing and growing a programming language, you’d probably be doing your existing user base a favor by prioritizing, stability, bug fixes and performance improvements over the constant addition of new features.
I think that what motivates the constant new feature additions we see in JavaScript, Python and Ruby and other languages is not purely a desire to help programmers be more productive, but also a drive to keep up with the Joneses and maintain some competitive edge over other languages. Language designers are worried that new users will flock to whichever language has the newest, trendiest features.
There is probably some truth to the idea that many newcomers will go for the latest features. However, on the flip side, I’ve been wondering if there can’t be a competitive edge in designing a language that is minimalistic, stable and slow to evolve by design. My personal preference is for languages that avoid hidden, complex, automagic behavior. I also think that there is value in choosing a syntax and semantics that uses broadly understood primitives. After all, the main value of a language is in being understood.
